编程和计算机知识的回顾
在进行数据处理时,我们会遇到许多问题,包括软件方面的、编程方面的,所有的问题都要尝试自己解决。要相信电脑不会出问题,一定是某个环节出错了。出了问题要善用搜索工具,在网上看看有没有人有相同的问题,他们是如何解决的。现在AI也很聪明,遇到报错可以将报错内容交给AI,应该可以得到解决。一定不要气馁,一定要找各种办法尝试解决。
想到了一个很古老的表情包:
本章包括以下内容:
Python光速复习
在分析时,我们常常需要自己编写一些脚本,需要自己写一点代码。Python是目前最火热的语言,教程、工具非常多,掌握这一门语言就可以解决许多问题了。众所周知,由于解释器的缘故,Python相比其它语言来说比较慢,但是这不是缺点。有个著名笑话:“对于同一个问题,我写Python花了1分钟,运行用了1小时,你写C花了1小时,运行用了1分钟。花费的总时间是一样的,但是我放松了一小时。”更何况对于我们的问题,运行可能一分钟都用不了,所以写的快更是优势。
这部分只适用于帮助有基础的同学回忆,并不适合入门。
对于我们的问题,Python掌握以下内容就足够了:
- 基本的数据类型和数据结构:str, number, list和dict
- 循环语句:while和for
- 条件控制语句:if else和switch case
- 函数
- IO的相关方法
其它的诸如类、装饰器等等都不需要掌握。
该部分还缺少日志、异常处理等内容,因为我也不会,但也不是大问题。
变量和常量
应该不用多说,大家都理解,在实际使用时,几乎没用过常量
变量的声明直接用=,变量名该怎么命名大家也都明白。命名规范有什么驼峰式、匈牙利式等等,大家可以自己看看。这个还是要注意一下的,不然过了两天就看不懂自己写的什么了。
解释器可以自己推断变量的类型,当然还是建议写上类型注解方便理解和问题排查。Python的一些工具也可以从类型注解中提前推断错误,避免犯错。直接在变量名后加上:和类型就可以了
字符串(Str)
就是一堆字符组成的串
可以用for遍历
>>> str1 = "This is a sentence."
>>> for i in str1:
... print(i)
...
T
h
i
s
i
s
a
s
e
n
t
e
n
c
e
.
可以直接截取
大家都明白Python下表是从0开始的,基本语法为str[a:b:c]其中a代表开始的字符,b代表结束的后一个字符,也就是这里a:b是一个左闭右开的区间。c代表步长,默认是1,如果为2就是跳着截取。
可以参考下图
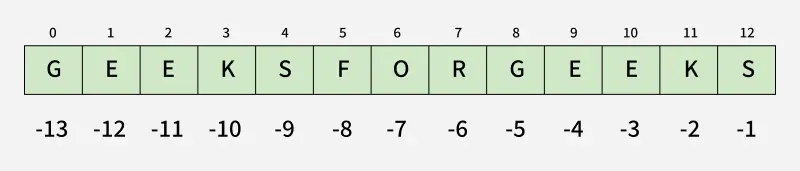
字符串相关运算符
这里直接粘一张别人的表
变量 a 值为字符串 "Hello",b 变量值为 "Python":
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | >>>a+b 'HelloPython' |
| * | 重复输出字符串 | >>>a*2 'HelloHello' |
| [] | 通过索引获取字符串中字符 | >>>a[1] 'e' |
| [ : ] | 截取字符串中的一部分 | >>>a[1:4] 'ell' |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | >>>"H" in a True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | >>>"M" not in a True |
多行字符串
三个"就可以了
Output
常用方法
upper()和lower()一个全大写一个全小写,都明白什么意思
split()这个很常用,尤其是在处理一些表格时
基本用法:
>>> str1: str = "A B C D E F G"
>>> print(str1.split())
['A', 'B', 'C', 'D', 'E', 'F', 'G']
>>> str1: str = "A|B|C D|E F|G"
>>>
>>> print(str1.split("|"))
['A', 'B', 'C D', 'E F', 'G']
括号内放要切的字符,例如是"|"就从根竖线开始切。切完的结果是一个由字符串构成的列表。
strip()这个也很常用,在处理文本文件时,我们要除去换行符等。
你可能会发现Python的字符串可以用str.function()这种方式操作,这其实说明python的字符串就是一个类。仔细想想其它的内置类型也有类似的特性,它们也是类。
列表(List)
列表是Python中最常用的数据结构之一,用于存储有序的元素集合。
创建列表
# 空列表
empty_list: list = []
# 或
empty_list = list()
# 包含元素的列表
numbers: list[int] = [1, 2, 3, 4, 5]
fruits: list[str] = ["apple", "banana", "orange"]
mixed: list = [1, "hello", 3.14, True] # 可以包含不同类型
基本操作
# 访问元素(索引从0开始)
fruits = ["apple", "banana", "orange"]
print(fruits[0]) # "apple"
print(fruits[-1]) # "orange"(倒数第一个)
# 切片操作
print(fruits[0:2]) # ["apple", "banana"]
print(fruits[1:]) # ["banana", "orange"]
# 修改元素
fruits[1] = "grape" # 列表变为["apple", "grape", "orange"]
# 添加元素
fruits.append("pear") # 末尾添加
fruits.insert(1, "kiwi") # 指定位置插入
# 删除元素
fruits.pop() # 删除最后一个元素
fruits.pop(1) # 删除指定位置元素
fruits.remove("apple") # 删除指定值元素
# 列表长度
print(len(fruits)) # 获取列表长度
常用方法
# 列表拼接
list1 = [1, 2, 3]
list2 = [4, 5, 6]
combined = list1 + list2 # [1, 2, 3, 4, 5, 6]
# 列表重复
repeated = [0] * 5 # [0, 0, 0, 0, 0]
# 查找元素
if "apple" in fruits:
print("找到了苹果")
# 排序
numbers = [3, 1, 4, 1, 5]
numbers.sort() # 原地排序
sorted_numbers = sorted(numbers) # 返回新列表
字典(Dict)
字典用于存储键值对,提供快速的数据查找能力。
创建字典
# 空字典
empty_dict: dict = {}
# 或
empty_dict = dict()
# 包含键值对的字典
student: dict[str, any] = {
"name": "张三",
"age": 20,
"major": "生物信息学"
}
scores: dict[str, int] = {
"数学": 95,
"英语": 88,
"编程": 92
}
基本操作
# 访问值
print(student["name"]) # "张三"
# 安全访问(避免KeyError)
age = student.get("age", 0) # 如果键不存在返回默认值0
# 修改值
student["age"] = 21
# 添加新键值对
student["grade"] = "大二"
# 删除键值对
del student["major"]
removed_value = student.pop("age") # 删除并返回值
# 检查键是否存在
if "name" in student:
print("姓名存在")
# 获取所有键和值
keys = student.keys() # 所有键
values = student.values() # 所有值
items = student.items() # 所有键值对
常用方法
# 字典合并
dict1 = {"a": 1, "b": 2}
dict2 = {"b": 3, "c": 4}
dict1.update(dict2) # dict1变为{"a": 1, "b": 3, "c": 4}
# 遍历字典
for key, value in student.items():
print(f"{key}: {value}")
# 字典推导式
squares = {x: x*x for x in range(5)} # {0: 0, 1: 1, 2: 4, 3: 9, 4: 16}
其它
字典还有所谓“深复制”和“浅复制”的区别,大家可以自己探索
for
不想写了,待更新
while
它的功能好像可以被for完全代替
操作符
大家都会,这里直接引用Python的文档。
Boolean Operations — and, or, not
| Operation | Result | Notes |
|---|---|---|
x or y |
if x is true, then x, else y | (1) |
x and y |
if x is false, then x, else y | (2) |
not x |
if x is false, then True, else False |
(3) |
Notes:
- This is a short-circuit operator, so it only evaluates the second argument if the first one is false.
- This is a short-circuit operator, so it only evaluates the second argument if the first one is true.
-
not has a lower priority than non-Boolean operators, sonot a == b is interpreted asnot (a == b), anda == not bis a syntax error.
Comparisons
There are eight comparison operations in Python. They all have the same priority (which is higher than that of the Boolean operations). Comparisons can be chained arbitrarily; for example, x < y <= z is equivalent to x < y and y <= z, except that y is evaluated only once (but in both cases z is not evaluated at all when x < y is found to be false).
This table summarizes the comparison operations:
| Operation | Meaning |
|---|---|
< |
strictly less than |
<= |
less than or equal |
> |
strictly greater than |
>= |
greater than or equal |
== |
equal |
!= |
not equal |
is |
object identity |
is not |
negated object identity |
对于数字的操作
| Operation | Result | Notes | Full documentation |
|---|---|---|---|
x + y |
sum of x and y | ||
x - y |
difference of x and y | ||
x * y |
product of x and y | ||
x / y |
quotient of x and y | ||
x // y |
floored quotient of x and y | (1)(2) | |
x % y |
remainder of x / y |
(2) | |
-x |
x negated | ||
+x |
x unchanged | ||
abs(x) |
absolute value or magnitude of x | abs() |
|
int(x) |
x converted to integer | (3)(6) | int() |
float(x) |
x converted to floating point | (4)(6) | float() |
complex(re, im) |
a complex number with real part re, imaginary part im. im defaults to zero. | (6) | complex() |
c.conjugate() |
conjugate of the complex number c | ||
divmod(x, y) |
the pair (x // y, x % y) |
(2) | divmod() |
pow(x, y) |
x to the power y | (5) | pow() |
x ** y |
x to the power y | (5) |
Notes:
- Also referred to as integer division. For operands of type
int, the result has typeint. For operands of typefloat, the result has typefloat. In general, the result is a whole integer, though the result’s type is not necessarilyint. The result is always rounded towards minus infinity:1//2 is0,(-1)//2 is-1,1//(-2) is-1, and(-1)//(-2) is0. - Not for complex numbers. Instead convert to floats using
abs()if appropriate. - Conversion from
float toint truncates, discarding the fractional part. See functionsmath.floor() andmath.ceil()for alternative conversions. - float also accepts the strings “nan” and “inf” with an optional prefix “+” or “-” for Not a Number (NaN) and positive or negative infinity.
- Python defines
pow(0, 0) and0 ** 0 to be1, as is common for programming languages. - The numeric literals accepted include the digits
0 to9 or any Unicode equivalent (code points with theNdproperty).
位的操作
Python里几乎用不上
| Operation | Result | Notes |
|---|---|---|
x \| y |
bitwise or of x and y | (4) |
x ^ y |
bitwise exclusive or of x and y | (4) |
x & y |
bitwise and of x and y | (4) |
x << n |
x shifted left by n bits | (1)(2) |
x >> n |
x shifted right by n bits | (1)(3) |
~x |
the bits of x inverted |
Notes:
- Negative shift counts are illegal and cause a
ValueErrorto be raised. - A left shift by n bits is equivalent to multiplication by
pow(2, n). - A right shift by n bits is equivalent to floor division by
pow(2, n). - Performing these calculations with at least one extra sign extension bit in a finite two’s complement representation (a working bit-width of
1 + max(x.bit_length(), y.bit_length())or more) is sufficient to get the same result as if there were an infinite number of sign bits.
条件语句
这个东西很简单,大家都明白,就是if else和switch case这个东西。其中match case用的很少。
if else
# 常见的就是
if condition:
# do something
else:
# do something
# 有一种可以放在一行的写法
a = 1
if a < 0: print("a is negative")
# 如果条件比较多可以用elif
a = 2
if a < 0:
print("a is negative")
elif a < 1:
# do something
elif a < 2:
# do something
else:
# do something
# 还有一种方法,在其它语言里似乎叫三目运算符
age = 20
s = "Adult" if age >= 18 else "Minor"
print(s) # 这里输出"Adult"
IO
input()和print()都很简单
我们都学过通过open()和close()来打开和关闭文件。
但一般我喜欢用下面这种方式来打开文件,因为可以不用自己关文件
函数
这东西最早出现就是为了实现代码的复用。比如我们常常需要处理fasta序列文件,如果每次都实现一下fasta的处理会非常麻烦,所以我们可以把它写成一个函数在,需要的时候直接调用。
函数的声明大家应该很清楚。这里注意python的函数体没有花括号{},而是用冒号和空格区分。有时写晕了可能会加个花括号上去。
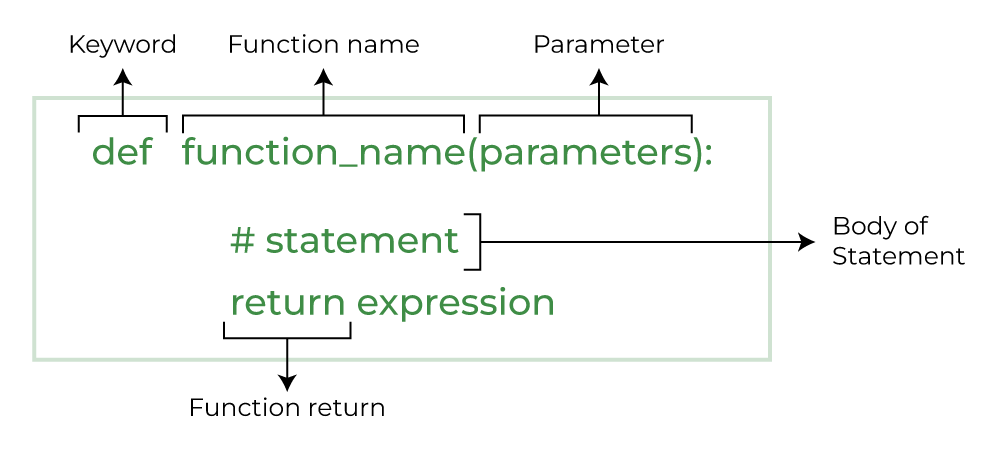
图片来源:Geeksforgeeks
# 函数可以设置默认参数,例如这样
def my_print(text = "Hahaha"):
print(text)
# 这样我们调用时
my_print()
# 结果为'Hahaha'
# 函数的变量可以有类型注释
def func2(text: str = "Hahaha") -> str:
return text*2
# 这样可以帮助我们理解函数的作用
怎么调用也应该很清楚
导入自定义模块
有时候我们发现有些函数我们经常使用,例如对于fasta文件的读取。这时候在每个文件里实现该功能就没有必要了,我们可以构建一个utlize.py文件,把这些常用的函数放进去,然后在其它地方调用。
注释
注释是非常重要的,否则过了两天就搞不懂自己的目的了。不利于我们研究的继续进行
python中的注释以#号开头。对于多行需要打上注释的情况,现在的ide都有快捷键帮助我们,选中要注释的行然后要按Ctrl+/就可以了。
运行
想不到这竟然是一个问题
这里说一下在vscode中运行的方法
方法一:打开终端运行
点击菜单栏中的终端->新建一个终端->终端中输入python3 ./script.py
这里输入的是python脚本的相对路径(因为直接在当前目录下)
当然有时会出现没有反应的情况,可能是因为没有把python的安装路径加入环境变量的path路径。这时需要手动添加一下。
方法二:直接点运行
安装并开启python插件后,插件应该能自动识别出python解释器。此时可以直接点击右上角运行

虚拟环境
在一般情况下,推荐使用虚拟环境。这是因为虚拟环境能够将当前项目所需的依赖环境与我们电脑中原本的系统环境完全隔离开来。
你可以把虚拟环境想象成一个“独立的工作室”——在这个空间里安装、升级或删除任何包,都不会影响到系统全局的 Python 环境,也不会影响其他项目。这样一来,不同项目之间就不会因为依赖版本不同而产生冲突,项目的运行环境也更加干净、可控。尤其是在ubuntu系统中,由于它的包管理器要用到python,所以不允许我们直接pip安装(防止把系统搞崩)。
虚拟环境有许多使用方式,这里介绍一个最简单的,也是Python自带的venv。
# 直接在目录下输入
> python3 -m venv venv_test
# venv_test是我们起的名字,一般情况下约定俗成使用.venv
# 创建好了我们来看一看
> tree -L 3
.
└── venv_test
├── bin
│ ├── activate
│ ├── activate.csh
│ ├── activate.fish
│ ├── Activate.ps1
│ ├── pip
│ ├── pip3
│ ├── pip3.12
│ ├── python -> python3
│ ├── python3 -> /usr/bin/python3
│ └── python3.12 -> python3
├── include
│ └── python3.12
├── lib
│ └── python3.12
├── lib64 -> lib
└── pyvenv.cfg
# 运行bin/activate就可以激活虚拟环境,windows下应该是在Script里
root@:.../home/experience_sum/my_project# source venv_test/bin/activate
(venv_test) root@...:/home/experience_sum/my_project#
# 前面出现了(venv_test) 表示在虚拟环境中
# 退出虚拟环境输入deactive就可以了
(venv_test) root@...:/home/experience_sum/my_project# deactivate
root@...:/home/experience_sum/my_project#
# 删除虚拟环境,直接删除创建的那个文件夹就可以了
rm -r venv_test/
调试
有时候程序并不是像我们想的那样运行,当然电脑是绝对没有错的,一定是我们哪里疏忽了。这时就需要利用好调试功能。
我们在安装python时会自带一个调试器PDB,是在命令行中使用的。因为PDB上手需要一定的基础,所以我们可以利用vscode来调试。
点击小三角旁的箭头,选择启动调试(这里是倒数第二个)
我们可以打断点,这样程序在运行到这的时候就会暂停,然后我们就可以检查问题了。
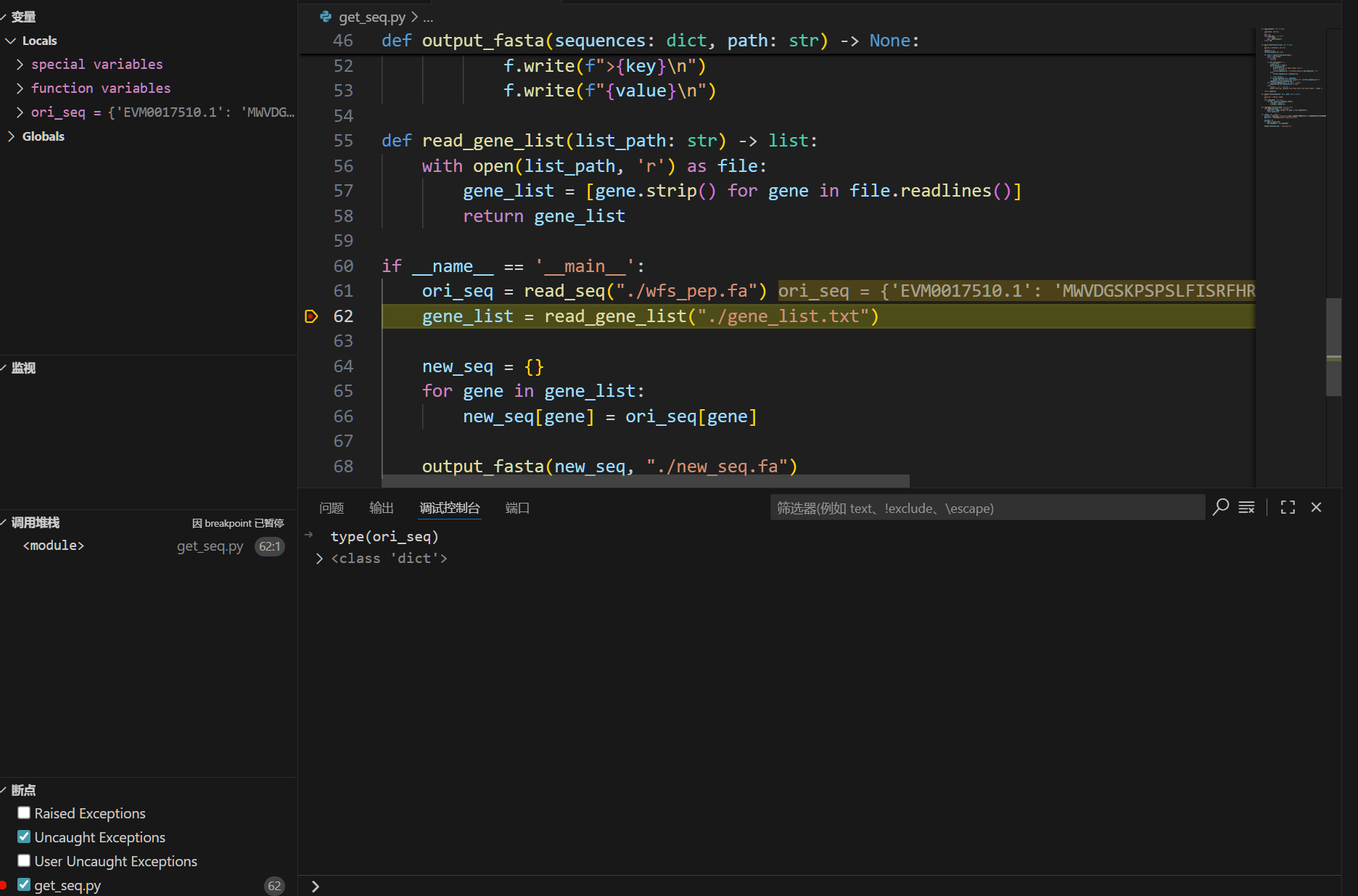
在左侧可以看到变量,在调试控制台里可以输入代码进行检查。
断点也不只一种,可以自行深入学习
风格
代码风格是无数人总结出来的优秀经验。可以自行在网上搜索学习。
Linux基础操作
linux是一个应用的很广泛的操作系统,最早是一个瑞典的一个研二的学生Linus Torvalds写出来的。
总之就是很常用。
关于底层的东西我们也不需要了解,只要知道怎么使用就可以了。
打开终端远程连接到系统上时,会看到这么一个东西

这个就是shell,外壳,我们通过它来使用电脑。shell本身也是一种软件,有bash, zsh, fish等,它们通常都是兼容的。自带的应该是bash。
网上还有人教我们怎么把这个黑黑的东西变得好看一点。
比如这样:
这样:
当然这些都是比较进阶的内容,这里不会涉及。感兴趣的可以自己上网搜索。
学会自行解决问题
所有的问题都要尝试自己解决,比如某个命令不会用,某项操作有问题
bash中有这样一个命令,man大概是manuscript的意思。
最简单的用法就是在后面加上你要学习的命令。比如让它自己解释一下自己
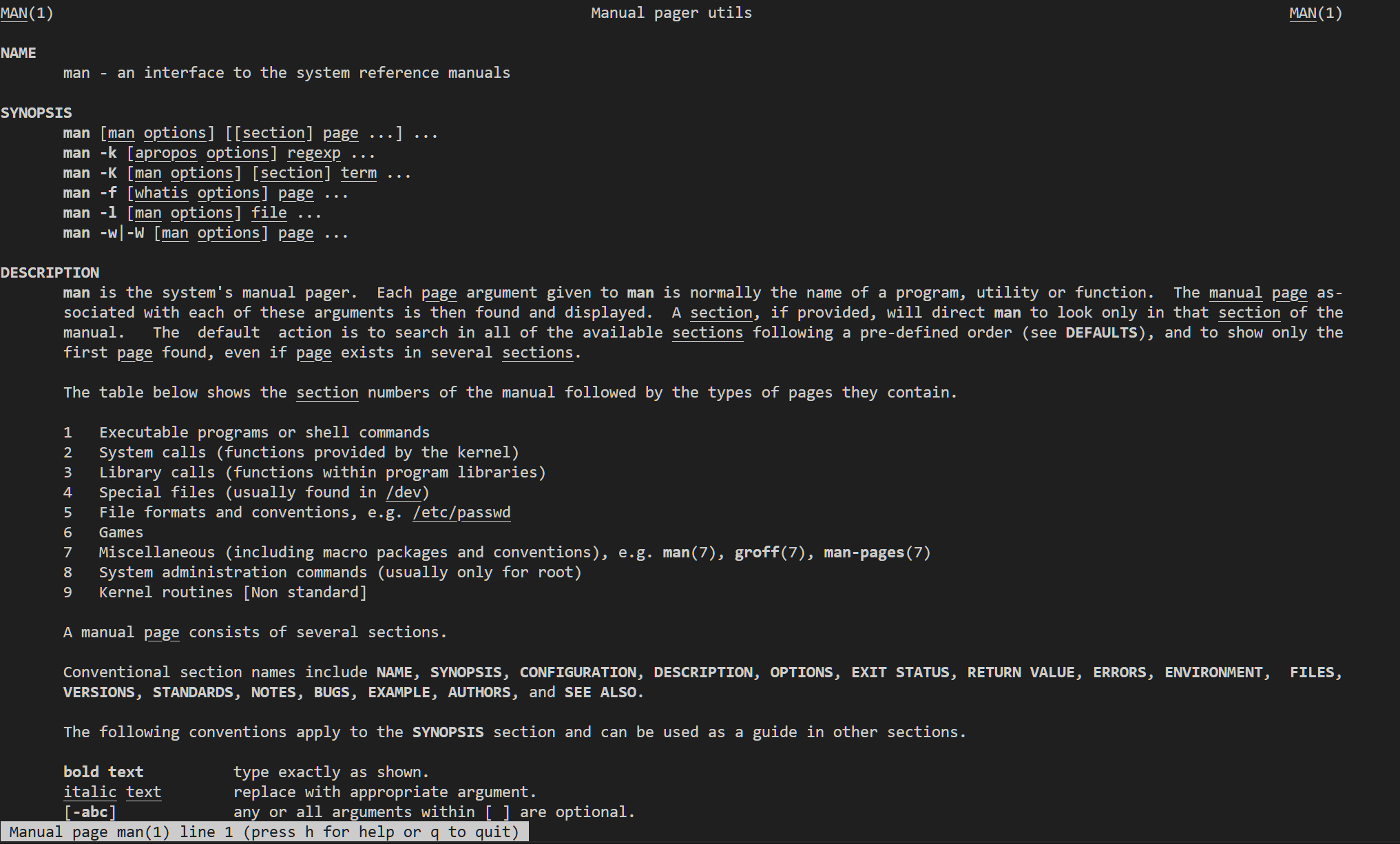
这里的内容很长很全面,按j和k或上下两个方向键可以上下翻面,按q退出
看看ls的作用,就输入man ls
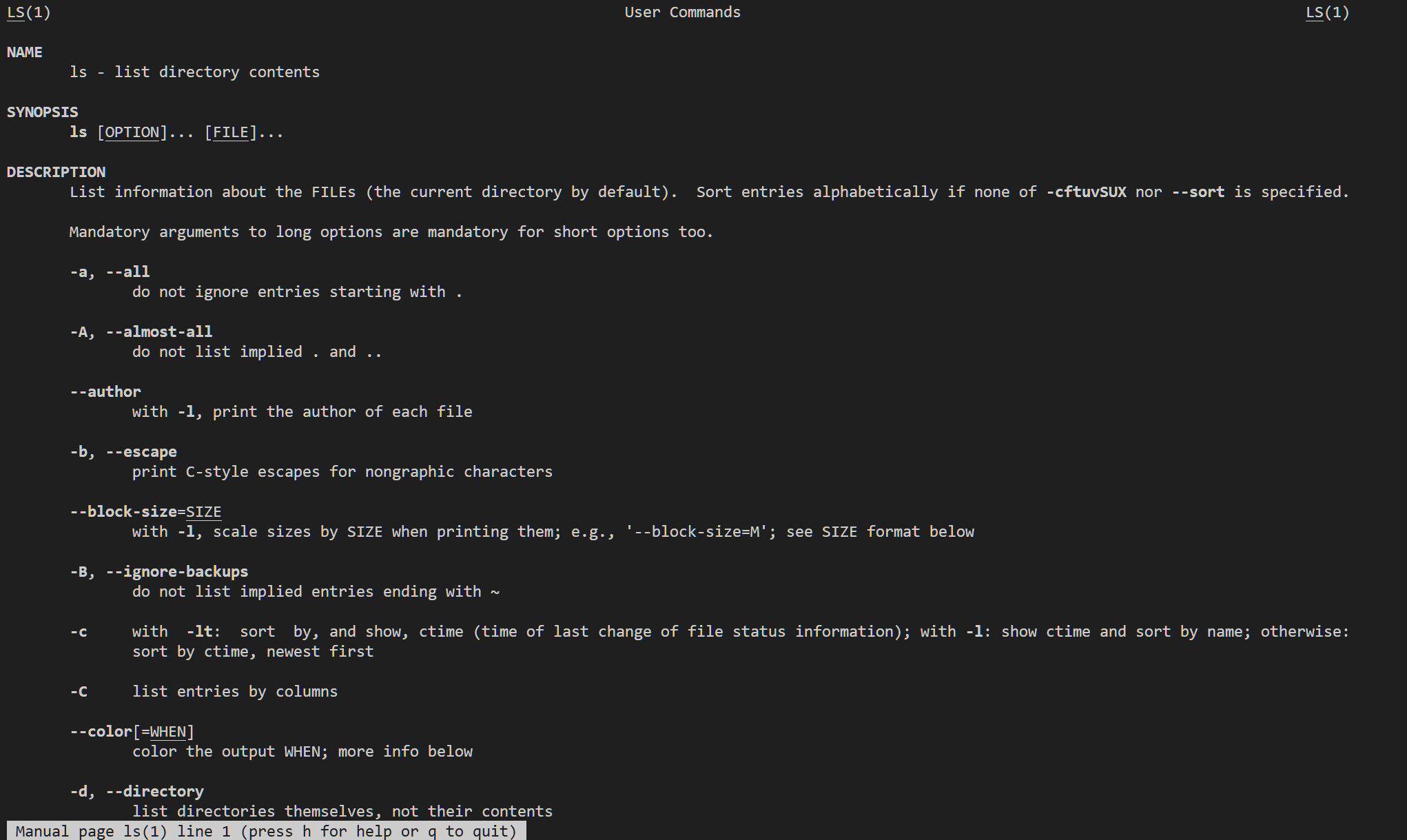
当然man的内容很多,我们想要快速了解的话还是有的慢。bash还有一个命令whatis,就是字面意思,使用方法也和man一样。但是它没有man全面,有很多命令没有收录

基础知识
众所周知,我们现在用的操作系统都是文件夹一层套一层的。我们打交道的通常就是一个黑框,因为图形化界面需要消耗性能。
我们用pwd(print working directory)可以输出当前所在的路径。
/home/experience_sum这就是路径
基础操作
一、文件和目录导航
-
pwd(Print Working Directory): 显示你当前所在的路径。 -
ls(List): 列出当前目录下的文件和文件夹。 -
ls -l: 显示详细信息(权限、所有者、大小等)。 -
ls -a: 显示所有文件,包括隐藏文件(以.开头)。 -
ls -h: 显示文件的大小更易懂,就是换了个单位(h大概是human的意思) -
cd(Change Directory): 切换目录。 -
cd /path/to/directory: 进入指定目录。 -
cd ..: 返回上一级目录。 -
cd ~ 或cd: 回到你的主目录 (home)。不同用户的主目录不一样
二、文件和目录操作
-
mkdir <目录名>(Make Directory): 创建一个新目录。 -
touch <文件名>: 创建一个空文件或更新文件时间戳(很形象,就是摸它一下)。 -
cp <源文件> <目标位置>(Copy): 复制文件或目录。 -
cp -r <源目录> <目标位置>: 复制整个目录(r代表递归)。 -
mv <旧名称> <新名称>(Move): 移动或重命名文件/目录。 -
rm <文件名>(Remove): 删除文件。 -
rm -r <目录名>: 删除目录及其下所有内容。 -
警告:
rm -rf 会强制删除且无法恢复,请极其谨慎使用!
三、查看文件内容
-
cat <文件名>: 显示整个文件的内容(适合小文件)。 -
less <文件名>: 分页查看文件内容,可上下滚动(按q退出)。 -
head <文件名>: 查看文件的前几行(默认10行)。 -
tail <文件名>: 查看文件的后几行(默认10行)。 -
tail -f <文件名>: 实时查看文件新增的内容,常用于看日志。
四、搜索
-
find <路径> -name "<文件名>": 在指定路径下按名称查找文件。 -
grep "<关键词>" <文件名>: 在文件中搜索包含关键词的行。
五、系统和进程
这个不常用
-
ps aux: 查看系统中所有正在运行的进程。 -
kill <进程ID>: 结束一个进程。 -
top 或htop: 实时动态地查看系统资源和进程状态。 -
df -h: 查看磁盘空间使用情况(-h使其易读)。
六、权限和执行
这个不常用
-
sudo <命令>: 以管理员(root)权限执行命令。 -
chmod +x <文件名>: 给文件添加可执行权限。
七、下载
-
wget: 从链接中下载文件
八、实用技巧
- Tab 键: 自动补全命令或文件名,非常高效。
-
管道
| : 将一个命令的输出作为另一个命令的输入。 -
例如:
ps aux | grep "chrome"(查找所有与chrome相关的进程)。 -
重定向
> : 将命令的输出结果写入文件(会覆盖原内容)。 -
例如:
ls -l > file_list.txt - 重定向
>> : 将输出结果追加到文件末尾。
包管理
在Linux世界中,我们通常不从网上随意下载 .exe 文件来安装软件。取而代之的是使用操作系统自带的包管理器(Package Manager) 。这可以理解为一个官方认证、安全可靠的软件商店,它负责处理软件的下载、安装、更新、依赖关系和卸载。
在Ubuntu及其衍生系统(如Linux Mint)中,这个强大的工具就是apt (Advanced Package Tool)。其它不同的发行版有不同的包管理器。
下面是使用apt安装软件(以tree为例)的步骤。tree是一个能以树状结构显示目录和文件的小工具,非常实用。
详细步骤
第1步:apt update,先刷新一下“商品目录”
在去“商店”买东西前,最好先拿一份最新的商品宣传单,看看都有啥、最新价格是多少。apt update做的就是这个事。
这个命令会连接到Ubuntu的服务器,把你本地的软件列表更新到最新。它不会安装或升级任何软件,只是刷新列表,但这一步非常重要,不然你可能会装不上软件,或者装了个很老的版本。
第2步:apt search tree,搜一下想装的软件叫啥
有时候你不确定软件的准确名字,用search搜一下就行。
(小提示:search一般不用sudo)
Sorting...
Full Text Search...
...
tree/noble,now 2.1.1-1 amd64 [installed]
displays an indented directory tree, in color
...
这里会出来一堆东西,简单翻翻。看到那个叫 tree 的,后面的描述是“displays an indented directory tree...”,差不多就是它了。确定名称就是tree。
如果你想看得更仔细点,比如想知道它多大、有啥依赖,可以用 apt show:
这就像看商品的详细说明书,确认一下没问题再“下单”。
第3步:sudo apt install tree,安装
找到想要的东西了,就可以直接安装了。
这时候,电脑会很贴心地告诉你:
- 除了
tree本身,可能还需要装一些其他它依赖的小零件(依赖包)。 - 所有这些东西装完总共要占多少硬盘空间。
- 最后问你一句
Do you want to continue? [Y/n](要继续吗?)
你只要自信地敲一个 Y 再按回车,然后等一小会儿,它就会自动下载安装好。
(懒人办法:如果你很确定,可以在命令后面加个 -y,它就不会问你了,直接装。sudo apt install -y tree)
第4步:检查一下是不是装好了
装完之后,总得确认下吧?很简单,直接在终端里敲一下这个命令:
如果它成功输出了版本号,那就说明tree已经安装成功,可以开始用了
顺便提一下:升级和卸载
软件管理,除了安装,还有升级和卸载。
- 给所有软件升个级:
(通常推荐先 update 再 upgrade)
- 卸载软件:
如果哪天你不用tree了,可以这样卸载它。
这个命令会删掉软件,但可能会留下一些配置文件。
- 卸载得更干净一点:
如果你想把配置文件也一起删掉,可以用purge。
卸载软件后,当初跟着一起装的那些依赖“小零件”可能就没用了,用下面这个命令可以把它们都清理掉,给硬盘瘦瘦身。
总结
软件安装流程可以概括为:
-
sudo apt update:更新软件“目录”,确保信息最新。 - (可选)
apt search <关键词> :查找不确定的软件包名称。 - (可选)
apt show <包名> :查看软件包详细信息以作确认。 -
sudo apt install <包名> :执行安装。 -
command --version 或 dpkg -l | grep <包名> :验证安装是否成功。
编译软件
我们经常遇到需要从源码编译的软件。关于具体如何编译安装应该看软件的文档,这里以MCScanX和HMMER做一个演示。
先看MCScanX文档中的installation部分
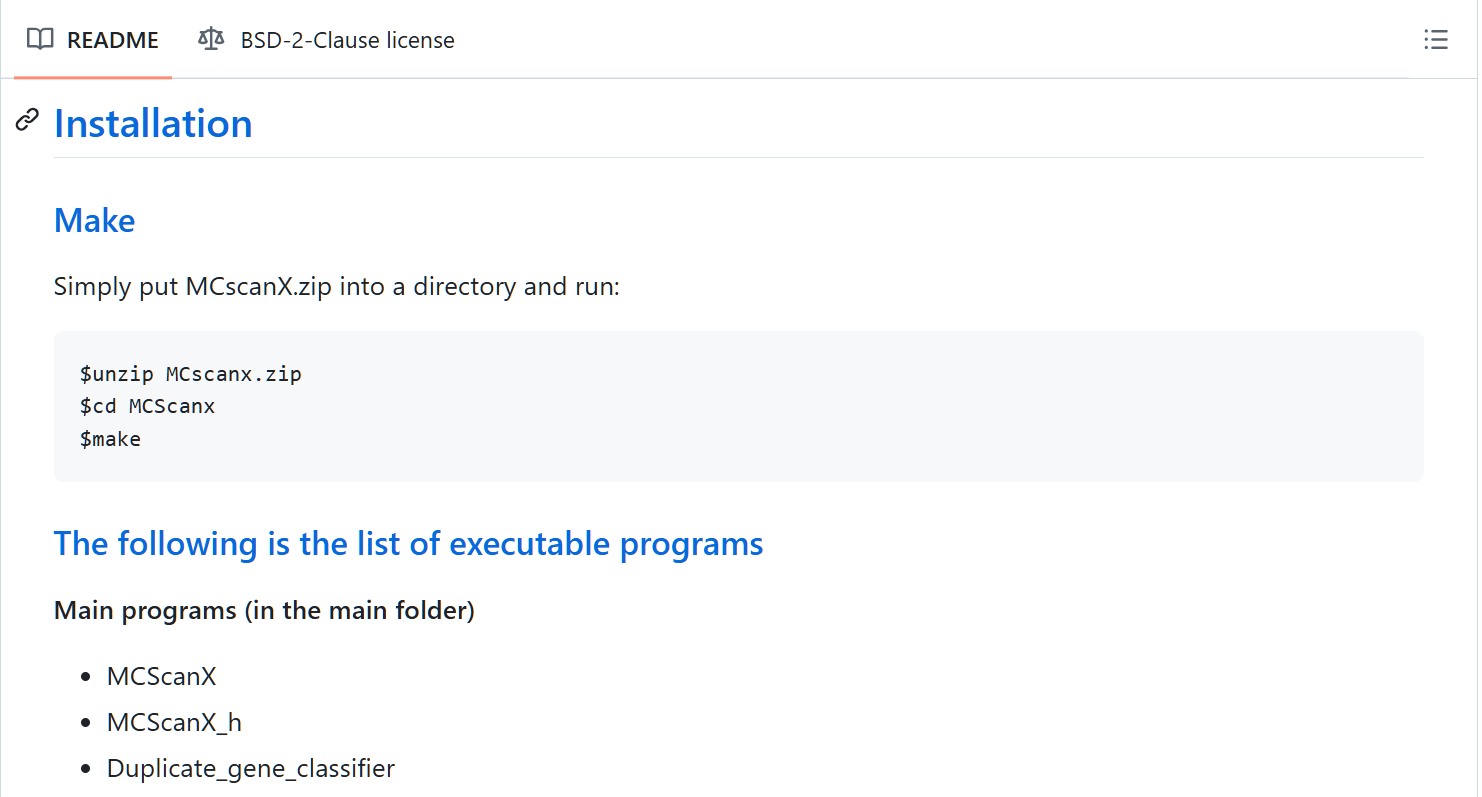
发现很简单,下载后解压,然后进入目录,输入make就完事了。还需要手动添加这个可执行文件的路径至环境变量,这样就可以在任何位置使用了。
写过C或C++的同学应该了解make。但对于不了解的同学,若要从头讲明白make、makefile乃至cmake,就不是几个小时能完成的了。
这里试着简单解释一下,不会涉及具体的语法。
什么是编译?
我们可能已经习惯了使用Python。当我们运行一个Python脚本时,Python解释器会一行一行地读取我们的代码,并实时地把它们翻译成计算机能懂的指令来执行(其实是翻译为字节码,然后给python虚拟机运行,所以人们常说python速度慢)。这叫做解释执行。
但我们现在接触的C或C++是编译型语言。我们用它们写的源代码(比如 .c 文件),计算机的CPU是看不懂的。因此,我们需要一个叫做编译器(Compiler)的程序,比如 gcc。
编译的过程,就是我们让编译器这个工具,把我们写的全部源代码一次性地、完整地翻译成CPU能直接执行的二进制指令,也就是机器码。这个翻译的结果,就是一个可执行文件(在Linux上通常没有后缀,比如 mcscanx;在Windows上就是.exe)。
有可能你会问既然都是由cpu执行,为什么不同操作系统的软件不通用呢?这又是一个复杂的问题,感兴趣可以自行搜索
这个翻译工作我们只需要做一次。之后,我们就可以直接运行这个生成好的可执行文件了,它的运行速度通常会快很多,因为它不需要再边读边翻译了。
简单对比一下:
- Python (解释) :我们写代码 -> 运行 -> 解释器边读边翻译边执行。
- C/C++ (编译) :我们写代码 -> 编译 -> 生成可执行文件 -> 运行可执行文件。
链接
当然我们看MCScanX的源码发现里面有许多.cc文件(这是C++源码),这和我们刚刚写的Python不同:为什么不把所有代码都写在一个大文件里呢?这主要是出于以下几个原因:
- 组织和维护性
就像我们写一本书会分成不同的章节一样,把代码按功能拆分到不同文件里,能让整个项目结构清晰。比如有一个file_io.c专门负责文件的读写,另一个algorithm.c专门负责算法的实现,
当我们需要修复一个关于文件读取的bug时, 我们就能立刻知道要去file_io.c这个文件里找问题,而不用在成千上万行的代码里大海捞针。这使得代码更容易阅读、理解和维护。 - 团队协作
如果所有代码都在一个文件里,两个程序员就很难同时对这个项目进行修改,他们会不断地覆盖对方的工作。而把代码拆分成模块后,小A可以专心修改blast_parser.c,小B可以同时优化algorithm.c,他们互不干扰,大大提高了开发效率。 - 代码复用
我们可能会写一个非常通用的模块,比如一个用于解析特定格式文件的parser.c。这个模块写好后,不仅可以在当前项目中使用,未来我们开发另一个新软件时,也可能需要同样的功能。这时,我们就可以直接把parser.c 和对应的头文件parser.h拷贝到新项目里复用,而不用重写代码。 - 提高编译效率
这一点非常关键,并且和make 直接相关。编译器的工作量是和代码行数成正比的。如果我们只有一个包含10000行代码的巨型文件,那么每次哪怕我们只修改其中一个字符,都必须重新编译整个10000行代码,这可能会花费很长时间。
但如果我们将项目拆分成20个每个500行的文件,当我们只修改了其中一个文件时,make的智能之处就体现出来了:它只会重新编译那一个被修改的500行文件,然后进行链接。其他19个未被修改的文件,会直接使用上次编译好的结果。这个过程可能只需要几秒钟,极大地加快了我们的开发和调试周期。
什么是“链接”,这些文件是怎样配合的?
好了,既然我们把代码拆分到了几十个文件里,那么新的问题就来了:在 main.c 文件里,我们可能会调用一个在 parser.c 文件里定义的函数。当编译器单独处理 main.c 时,它并不知道那个函数的具体实现在哪里。这些独立的文件是如何最终协同工作,形成一个完整的程序的呢?
答案就是链接 (Linking) 。
我们可以把整个编译安装过程分解为两个主要阶段:编译和链接。
完整来说对C或C++应该是:预处理、编译、汇编、链接。不过我们不用了解
-
第一阶段:编译 (Compilation)
当我们运行make 时,它会首先对每一个.c 源文件进行单独的编译。
gcc -c main.c -o main.o
gcc -c parser.c -o parser.o
gcc -c another_file.c -o another_file.o
...等等这个
-c 参数非常关键,它告诉编译器:“只做编译工作,不要进行链接。把这个源文件翻译成机器码,然后生成一个叫做‘目标文件’(Object File)的东西,它的后缀通常是.o。”现在,我们就得到了一大堆
.o 文件。每一个.o 文件都是一个半成品,是对应.c 文件的机器码版本。它们就像一块块独立的乐高积木。main.o 可能知道它需要一个叫parse_file 的功能,但它只有一个“接口”或“插槽”,并不知道这个功能的具体实现在哪里。而parser.o 则包含了parse_file功能这个“凸起”,但它不知道谁会来使用它。 2. 第二阶段:链接 (Linking)
在所有源文件都被编译成目标文件后,make 就会调用一个叫做链接器 (Linker) 的程序(通常也是通过gcc 命令来间接触发)。
gcc main.o parser.o another_file.o -o mcscanx链接器的工作就像是拼装乐高模型的最后一步。它会:
- 收集所有我们给它的
.o文件。 - 解析符号:它会检查
main.o 里的那个parse_file “插槽”,然后在所有其他的.o 文件里寻找,直到在parser.o 里找到了parse_file这个“凸起”。 - 地址重定位:找到之后,链接器就会把这个“插槽”和“凸起”严丝合缝地连接起来。在技术上,它会把函数调用的地址指向函数实现的实际地址。
- 合并:最后,它把所有这些已经连接好的、完整的机器码打包在一起,形成一个单一的、完整的、可以独立运行的可执行文件,也就是
mcscanx。
- 收集所有我们给它的
所以,整个流程是:
源代码 (.c 文件) -> [编译器] -> 一堆独立的半成品 (.o 文件) -> [链接器] -> 一个完整的可执行文件
通过这种“先分后合”的方式,我们既享受了把代码拆分成多个文件带来的各种好处,又能通过链接这个关键步骤,把所有分散的部分组合成一个能协同工作的强大程序。
为什么要用 make?
像MCScanX这样的软件,它的源代码可能由几十个 .c 文件组成。如果我们自己手动编译(也就是自己打那些命令),那将是一场灾难。我们需要对每一个 .c 文件单独执行编译命令,生成中间文件(.o 文件),最后再把所有这些中间文件“链接”成一个最终的可执行程序。
这个过程不仅命令繁多,而且只要我们搞错一个顺序或漏掉一个文件,就会失败。为了把程序员从这种繁琐重复的工作中解放出来,就有了 make 这个自动化工具。
学会省懒是很重要的
make 和 Makefile
-
Makefile:我们可以把它看作一个说明书或一个脚本。软件的开发者已经为我们写好了这个文件。它里面详细定义了一系列规则,告诉make这个工具: -
我们的最终目标是什么?(比如,生成
mcscanx这个可执行文件)。 - 要达成这个目标,需要先完成哪些准备工作?(比如,需要先把
a.c,b.c,c.c ... 分别编译成a.o,b.o,c.o...)。 - 完成每一步具体需要执行什么命令?(比如,用
gcc -c a.c -o a.o 来生成a.o)。 -
make:这是一个程序。当我们在命令行里输入make 时,它就会自动去当前目录下查找Makefile这个“说明书”,然后严格按照里面的规则,一步步执行所有必要的编译和链接命令。
make还有一个非常智能的特点:它会检查文件的新旧。如果我们只修改了其中一个源代码文件,然后再次运行make,它只会重新编译我们修改过的那个文件以及与它相关的部分,而不会把整个项目从头到尾再编译一遍。这为我们节省了大量的时间。
所以,当MCScanX的文档让我们直接运行 make 时,意思就是“我们已经为你准备好了完整的自动化编译脚本,你直接运行它就行了”。
为什么还需要 cmake?
现在,我们可能会遇到一个新问题。Makefile 这个说明书虽然好用,但它通常是针对某个特定的系统环境(比如特定版本的Linux)写的。如果我们的电脑是macOS,或者另一个Linux发行版,那么编译器名字、需要的库文件存放位置可能都不一样,直接用原来的Makefile就可能会出错。
对于更复杂的软件,它们需要能在各种各样的系统上成功安装。为了解决这个问题,我们就需要 cmake 这样的工具。
就是更加省懒
-
CMakeLists.txt:在这种情况下,开发者不直接给我们Makefile。他们提供的是一个更通用的项目描述文件,叫做CMakeLists.txt。这个文件只描述了项目本身的信息,比如“我们有哪些源文件”、“我们需要一个叫zlib的库”等等,但它不包含写死的、针对特定系统的编译命令。 -
cmake:这个程序的作用,就是读取CMakeLists.txt,然后自动侦测我们当前的系统环境。它会检查我们的操作系统是什么、编译器装在哪里、zlib库又在哪里等等。在完成所有检查之后,它会根据这些信息,为我们量身定制一份适合我们当前系统的 Makefile。
所以,对于使用 cmake 的软件,我们通常的安装步骤就变成了两步:
-
cmake . (或cmake ..):让cmake检查我们的系统,并生成一份本地化的Makefile。 -
make:现在我们有了一个可用的Makefile,就可以用make来完成最终的编译工作了。
一些老牌软件可能不用 cmake,而是用一个叫 ./configure 的脚本,它的功能和 cmake 几乎一样,也是先检查环境,再生成 Makefile。
总结一下要点:
- 编译:这是一个一次性的过程,我们用编译器把源代码转换成机器能直接运行的程序。
-
make:一个自动化工具,它读取Makefile里的规则,帮我们完成所有编译和链接的命令(不用手输gcc了)。 -
Makefile:一份为make准备的详细的编译说明书,规定了如何从源代码生成最终的程序。 -
cmake 或 ./configure:更高级的工具,它们会先检查我们的系统环境,然后自动生成一份适合我们电脑的Makefile。
简单来说,程序员为了避免手打一堆gcc ...出现了make,它可以按照makefile来自动运行这些gcc ...。然后程序员又觉得手写makefile麻烦,又发明了cmake来自动生成makefile。
作为使用者,我们的核心任务就是仔细阅读软件的文档,按照开发者给出的步骤操作。如果中途报错,通常是我们的系统里缺少了某个“依赖库”,根据错误提示把它安装好,问题一般就能解决。
可能会问的一些问题
编译出来的是个啥?
我们编译完成的是可执行文件,也就是能直接运行的软件。很显然它与我们在windows上的不同。这是系统的差异,windows下的可执行文件为pe格式,后缀为exe。linux下的叫elf,一般没有后缀。具体有许多细节,感兴趣可以自行了解。所以一般情况下我们windows系统中的exe是没办法放到linux下运行的,反之亦然。
想给它挪个位置,可以直接用mv吗?
具体得看文档。正如我们所见,编译的结果不是只生成一个可执行文件,可能有几个可执行文件,还有一些打配合的文件。所以不要直接移动这个可执行文件。
(添加至环境变量)
在编译好软件之后我们可能还需要添加路径至环境变量。假如我们输入ls这时会打印当前目录下的文件,这个命令可以使用因为我们的系统知道有ls这个东西,并且知道它在哪里。
# 例如输入which来查找ls在哪里
>which ls
/usr/bin/ls
# 可以看到在这个路径里
# 再用file看一下ls到底是什么
>file /usr/bin/ls | tr "," "\n"
/usr/bin/ls: ELF 64-bit LSB pie executable
x86-64
version 1 (SYSV)
dynamically linked
interpreter /lib64/ld-linux-x86-64.so.2
BuildID[sha1]=3eca7e3905b37d48cf0a88b576faa7b95cc3097b
for GNU/Linux 3.2.0
stripped
# 可以看到是一个elf,也就是linux中的可执行文件
Screen
这个值得单独拎出来说
在我们进行一些长时间的处理时,为了不耽误事,我们可以将时间长的任务放在一个screen里让任务自己去跑,我们继续我们的工作。就如同windows里的窗口一样,可以将任务最小化放在状态栏里不耽误我们使用电脑。
掌握三个参数就够了,剩下的可以自己探索
screen -S screen_name直接输入-S加一个名称就可以启动一个新的screen了。要退出需要按ctrl+a再加上Ctrl+d,要关闭这个screen按Ctrl+a加Ctrl+k。
screen -r screen_name返回启动了的screen
screen -ls看看启动了多少screen
本人有一次连接远程服务器跑一个时间很长的任务,启动了以后就去睡觉了。过一会电脑自动休眠了,然后网络就中断了,ssh也断了,服务器发现连接断了之后就自动暂停了任务。结果就是睡了一觉发现任务几乎没有进展,还得从头做。所以学会用screen是很重要的。
正则表达式
这里只放一个参考表,会用的用自然会,不会的也不容易教(因为我也不喜欢用正则)。
[ ]
框住匹配的字符
直接打字符,序列
还有否定匹配
a[asd]d,即匹配aad,asd,add
a[a-z]d
a[^ab]d
+*?
- 1至无限
* 0至无限
? 0或1
.
匹配任何字符
{}
表示出现的次数
be{2}r,即beer
be{3,}r,即e出现三次以上
be{1,3}r,区间,容易理解
()
用来分组
括号 (?: ): 非捕获分组
插入符 ^:
匹配字符串的开始
美元符号 $:
匹配字符串的结束
\
\w
字母、数字和下划线
\W
非字母、数字和下划线,也就是其他符号
\d
匹配数字
\D
\s
\S
(?=) (?!)